

Introduction
So a lot of big words were used in the title. What does memoization mean? What does ReDoS mean? Fear not, young padawan, for everything will be revealed in the next couple of minutes.
To understand ReDoS we first have to define a regular expression (regex), which creates our first part of ReDoS. A regex is a sequence of characters that define a search pattern. Usually such patterns are used by string-searching algorithms for “find” or “find and replace” operations on strings, or for input validation.
Now that we have an idea what a regex is, we must now switch our focus to the DoS component in ReDoS. DoS stands for Denial-of-Service. The term is widely used in the networking department of computer science. A DoS attack on a service (such as a website) disrupts its normal function and prevents other users from accessing it.
So, when adding regex and DoS, the concept of ReDoS is born. In plain terms: there are regexes that can used in a Denial-of-Service attack.
Problematic Regexes
A problematic regex is a regex that leads to an epsilon loop if we regard the regex as an NFA. Okay, so we’re back to fancy words, so let’s first talk about what an NFA is. An an example, picture 4 locations. Let’s say you have your house, nearby restaurant, mall and pub chosen as places and there is only one route to each place from the previous place as shown in the undirected graph.
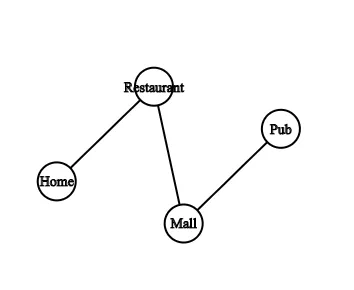
In this graph above, each of the places is a node with an edge between them. In an NFA we can have multiple routes from a node to another, exactly like a normal road where there are multiple ways to drive. The figure below illustrates an example of an NFA consisting of 4 nodes and 4 directed edges (i.e. you can only move in the direction of one arrow).
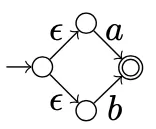
Two of the edges have an ε (epsilon) on the edge, which means once we enter the NFA (from the left) we simultaneously go to both the upper and lower node in the middle. From there we can go to the final node (on the right) if we have the input (a | b) which means a OR b.
Now that we have an extremely vague idea of what an NFA is, we can look into what epsilon loops are. We are going to look at the NFA that represents (a | a)* which means a OR a repeating 0 or more times.
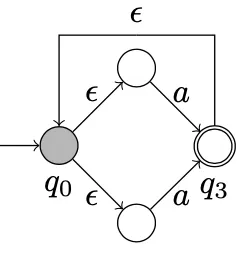
As we can see from above we start at the left again then go up and down at the same time. From there we go the final state with an a. This is via the upper or lower node. We should be finished now, but the upper epsilon takes us back to the start. So, are we stuck or what can we do?
Memoization
Firstly let’s define memoization, it is an optimization technique used primarily to speed up computer programs by storing the results of expensive function calls and returning the cached result when the same inputs occur again. By using this technique we can reduce the cost of traversing the whole NFA (yip, those two edges) to a single return. We must keep track of the inputs and their corresponding outputs, so this will cost us some space. Sadly I am not referring to the place with pretty stars, but more to the fancy word computer scientists use to describe memory usage. (No one knows why they use all these fancy words).
We want to memoize as long as we are reading input. For the above regex the need for memoization doesn’t seem clear, but let’s take a regex like
^([0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*@(0-9a-zA-Z)[-\w]*[0-9a-zA-Z]\.)+[a-zA-Z]{2,9}$
for example. No need to get into details here, but one can imagine that it will take some time to match certain input strings.
Back to memoization. There are multiple ways to implement memoization but one of the most efficient is to use a hash table. A Hash Table is a data structure which stores data in an associative manner. In a hash table, data is stored in an array format, where each data value has its own unique index value. Now we get pretty-fast access times, and we only pay for the space we use. We can further optimize this by using various techniques, but…

Conclusion
Regexes are very powerful and can be used for a lot of good. Unfortunately, one needs to careful of how you use it since it can lead to catastrophic damages through Denial-of-Service. Okay, maybe catastrophic is a bit hyperbolic, but if you’re running a business which has to validate emails and passwords for new users but due to ReDoS they have have to wait minutes for validation then they could quickly dislike your website. Luckily, memoization is here to the rescue from this conundrum by effectively reducing the strain that problematic regexes can have on a server, machine or program. Now that you’ve learned some ways as how to memoization can implemented, the world is you oyster!